Last night at my Public Interest Tech Case Studies class, our guest speaker was Dr. Tina Hernandez-Boussard of Stanford School of Medicine. She is a multi-hyphenate: doctor, epidemiologist, and researcher who works on how AI algorithms are being developed and deployed in health care. One of her lines of work is looking at whether the AI applications being deployed in medical work are not only technically robust, but also ethical, human-centered, and socially just.
The promise of AI in medicine is huge: if researchers, machine learning experts, and clinicians can draw on all of the past data of patients, symptoms, treatments, and outcomes — they may be able to offer better, quicker, more intelligent help to people who are struggling with illness.

Dr. Hernandez-Boussard identified 3 main tracks that medical professionals are using AI for. These may be analogous to legal tracks that are beginning, or may begin soon, for legal help & AI. They are:
- improving biomedical research (like in surfacing important findings from researchers, and links between studies),
- doing translational research (like in how the genome affects diseases and outcomes), and
- improving medical practice (like in how diseases are diagnosed, treatments are selected, patients are monitored, and risk models of disease/outcomes are built)

What potential is there for AI for Access to Justice?
This third track is perhaps the most exciting one for those of us focused on access to justice. What if we could better spot people’s problems (diagnose them), figure out what path of legal action is best for them (treat them, or have them treat themselves), and determine if their disputes are resolved (monitor them)?
Our Legal Design Lab work with Suffolk LIT Lab is already working the first thread, of spotting people’s problems through AI. We had collaborated on building Learned Hands, to train machine learning models to identify legal issues in people’s social media posts. That’s led to Suffolk LIT Lab’s SPOT classifier, that is getting increasingly accurate in spotting people’s issues from their sentences or paragraphs of text.
This medical scoping of clinical AI uses could inform future threads, aside from issue-spotting, for legal aid groups, courts, and other groups who serve the public:
- Legal Treatment AI: Can we build tools that predict possible outcomes for a person who is facing a few different paths, regarding how to resolve their dispute or issue? Like a tenant who is having problems with a landlord making timely repairs: should they call an inspector, file for rent escrow, try to break their lease, use a dispute resolution platform, or do nothing? What would be the time, costs, and outcomes involved with those different paths? Many times people seek out others’ stories to get to those data-points. What has happened when other people take those steps? AI might be able to supplement these stories with more quantitative data about risks and predicted outcomes.
- Problem Monitoring AI: Can we build tools that follow up on a person, after they have interacted with legal aid, courts, or other government institutions? Did their problem get resolved? Did it spiral into a bigger ball of problems?
The need for community design + ethical principles in AI development
That said, with the promise of these medical-inspired threads of legal help AI — Dr. Hernandez-Boussard warned of the importance of careful design of the AI’s purpose, data sources, and roll-out.
The danger is that AI-specialists develop new algorithms simply because it is possible to do so with available data sets. They may not think through whether this new tool (and the data it’s based on) is representative of the general population and its diverse demographics. They may not think whether clinicians would actually use this algorithm — whether it solves a real problem. And they may not think about unexpected harms or unequal benefits it might result in, for the patient.
This shows up with algorithms that detect heart failure in men, but don’t work at all for women. This is because the data the algorithms were trained on, is based on trials populated mainly by white men. Their symptoms for heart attacks are markedly different from women’s symptoms. So the model doesn’t detect women’s risks accurately, and may result in women not getting the prioritized care or appropriate treatment. A similar story is developing in regard to skin cancer screenings, in which the dataset training the AI is mainly from fair-skinned patients. Thus, the tool likely won’t be as effective for screening cancer in darker-skinned patients.

AI built on non-representative data, or rolled out with too much trust in its predictions, may result in poor care, bad outcomes for unrepresented groups, and less overall trust in the health system (and the AI).
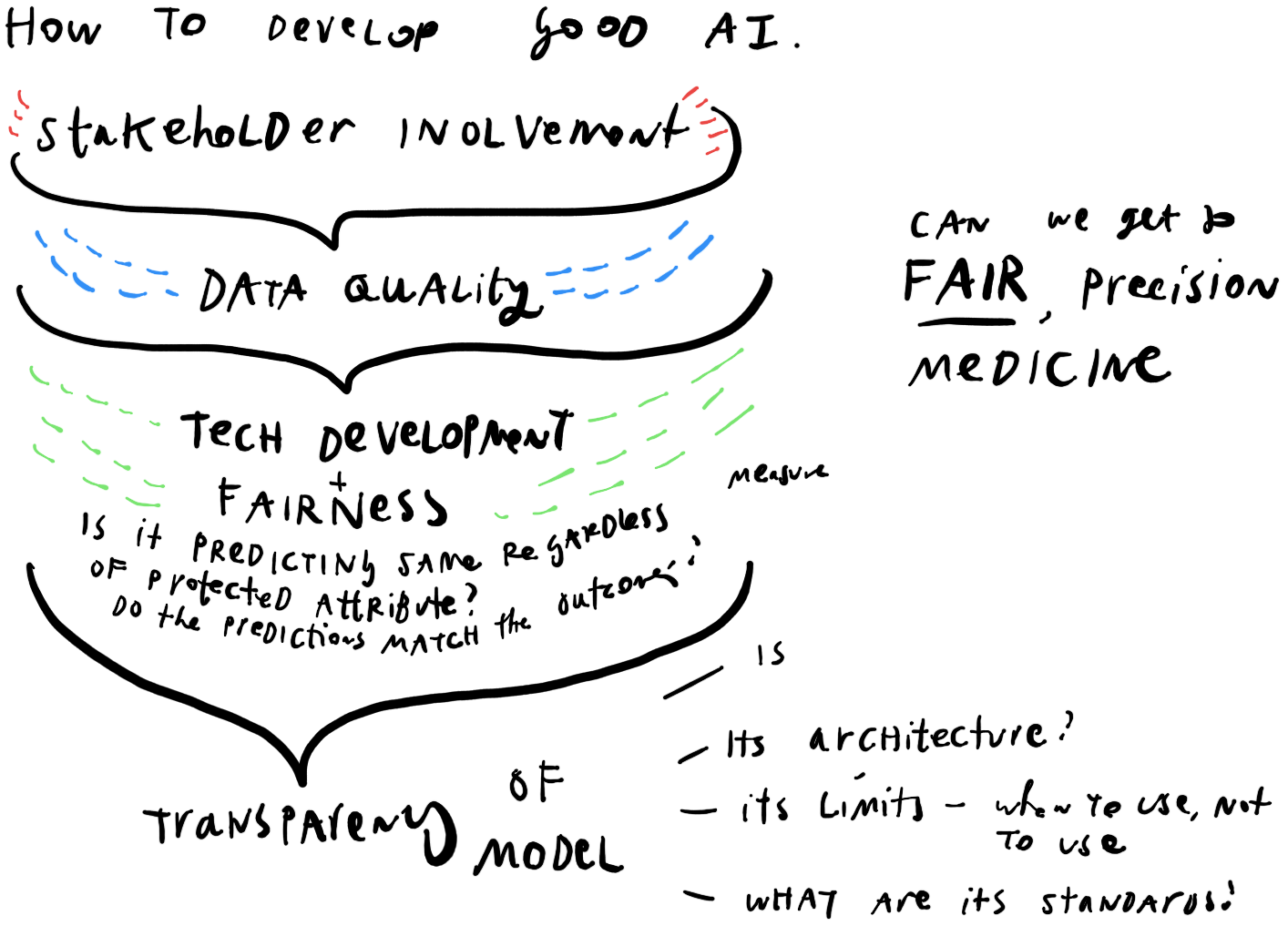
Dr. Hernandez-Boussard is working on a better framework to think through the development of AI for clinical care.
- Stakeholder Involvement in scoping the AI project, setting standards, and limits
- Data cleaning, quality-checking, and pre-processing — to make sure the data is as recent, accurate, representative, secure, etc. as possible
- Development of tech and testing of its fairness — to make sure that it is making accurate predictions, especially across protected classes of gender, race, etc.
- Rolling out the AI to be transparent and usable — so that practitioners don’t over-rely on it, use it for problems it wasn’t meant to solve, and to make it comprehensible and usable to patients and their care teams
This involves early, deep stakeholder involvement. In this phase, there are critical discussions about whether AI is needed at all, what important questions it can answer, and whether clinicians and patients would actually use it on the ground.
The promise of co-design in AI development
This phase is where legal design could shine in AI/A2J work. Co-design, participatory design, and community-led design methods are meant for this type of broad stakeholder conversations, agenda-setting, and principles-setting.

Legal design is also essential in the fourth phase of development: how is the AI rolled out to people on the ground who should be using it to make decisions. Do they know its limits, its standards, and its sources? How can they be sure not to over-rely on it, yet still build trust in what it is able to do? And how do they help overwhelmed patients make sense of its predictions, risk scores, and lists of percentages and possible outcomes?
Are you interested in learning more about ethical AI in healthcare, and how it might be used in other fields like legal services? Check out these upcoming events and online courses:
- There is a new Coursera course, Evaluations of AI Applications in Healthcare: https://www.coursera.org/learn/evaluations-ai-applications-healthcare. This starts on Jan. 25, 2021.
Its description: With artificial intelligence applications proliferating throughout the healthcare system, stakeholders are faced with both opportunities and challenges of these evolving technologies. This course explores the principles of AI deployment in healthcare and the framework used to evaluate downstream effects of AI healthcare solutions.
- On Feb. 9, 2021, there is a free webinar from Stanford medicine, Bringing AI into Healthcare Safely and Ethically: https://learn.stanford.edu/bringing-ai-into-healthcare-webinar.html
Its summary: Artificial intelligence has the potential to transform healthcare, driving innovations, efficiencies, and improvements in patient care. But, this powerful technology also comes with a unique set of ethical and safety challenges. So, how can AI be integrated into healthcare in a way that maximizes its potential while also protecting patient safety and privacy?
In this session faculty from the Stanford AI in Healthcare specialization will discuss the challenges and opportunities involved in bringing AI into the clinic, safely and ethically, as well as its impact on the doctor-patient relationship. They will also outline a framework for analyzing the utility of machine learning models in healthcare and will describe how the US healthcare system impacts strategies for acquiring data to power machine learning algorithms.

