
I have been working on the giant effort to make a comprehensive, user-centered taxonomy of legal issues that people have in the US. It’s called LIST, Legal Issues Taxonomy, and up in its growing glory at the site https://taxonomy.legal.
Note: this new taxonomy was previously called National Subject Matter Index v2 (NSMIv2), since it’s built from the early-2000s work from legal aid groups to make standard codes for their work, called the National Subject Matter Index (NSMI v1).
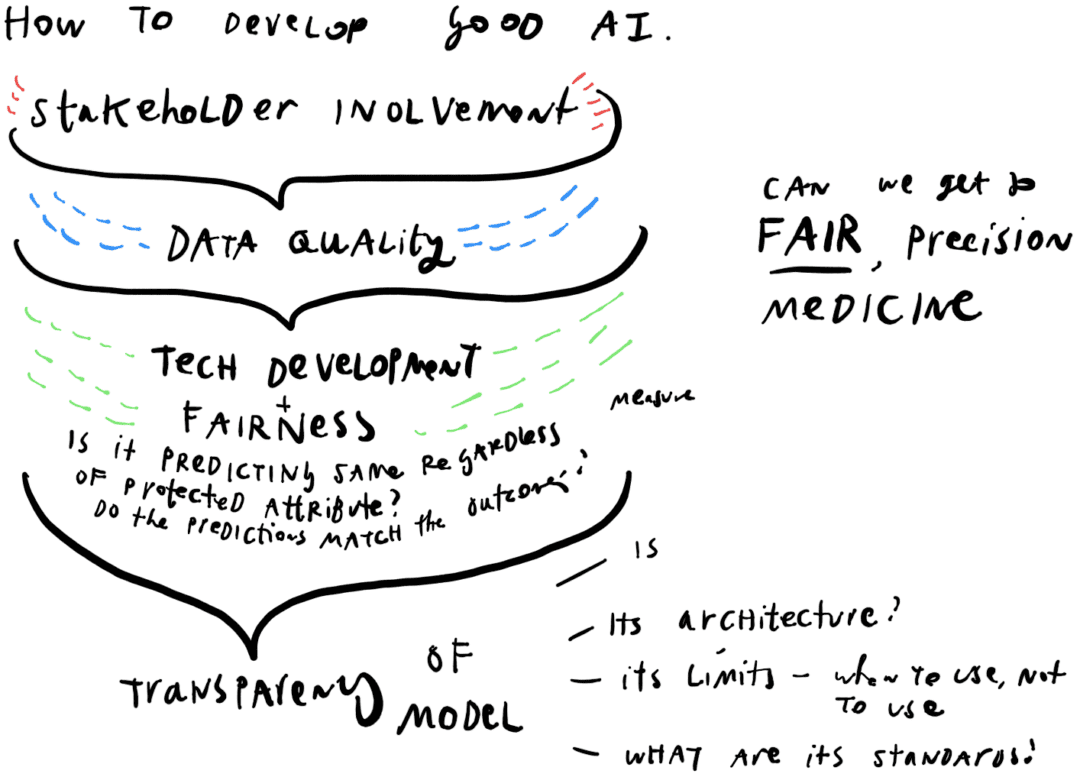
As I’ve been building out this taxonomy, I’ve been researching how we can be evaluating the quality + impact of a taxonomy project.
The Legal Issues Taxonomy has been built primarily to help those working on legal apps, machine learning projects, and web development to have standard codes. These can help them consistently label problems, develop classifiers, and create interoperable and smarter resources for people seeking help.
But as we know from other AI, tech, and infrastructure projects — well-intentioned efforts can have unexpected harms. Particularly for vulnerable groups, do seemingly technocratic efforts like taxonomies + AI classifiers have concerning impacts on equity, access, or bias?
To that end, upon the recommendation of Open Referral‘s Greg Bloom, I have been reading the MIT press book Sorting Things Out: Classification and its Consequences by Geoffrey Bowker and Susan Leigh Star.

It’s not the most casual summer read, but it’s been helping me define the ways we can evaluate a taxonomy’s effectiveness and watch for possible harms of this big ‘boring’ thing. (Note: I don’t find them boring, but I’m guessing that most people do….)
One of the big insights I’ve pulled from the book:

That’s one of the big ethical concerns for any taxonomy. Are you listing out problems for a particular demographic group, and ignoring those experienced by others? If there’s not a code and an official name for a person’s justiciable issue, does it exist in the legal community’s consciousness and services?
This could also be called the danger of Selective Invisibility: Does this legal taxonomy hide important categories of problems, and make it less likely that people will have these problems resolved or that there will be government to solve them?
Or to tie it back into legal academia, we need to have a full, rich, equitable list of names for legal issues — so that people can use them to name, blame, and claim — to get to access to justice.
Then there are more technocratic measures — of whether the taxonomy is even going to be used and useful in the first place. These questions are more about sorting out bugs and usability issues, to make a taxonomy that’s going to survive (many do not… they get built and quickly forgotten).
These questions go to the 3 categories that Bowker + Star highlight as the constant push-and-pull of taxonomy creators: Control, Comparability, and Visibility. A good taxonomy does all 3 of these, though they can never do all fully:
-
Control: Does the taxonomy + its platform give the users some amount of control? Channels to give feedback, edit, add on?
-
Comparability: Are the terms + taxonomy setup made standard enough, that they are used similarly at different groups and work sites? Can users consistently match the taxonomy term with its definition? If they have to fill in the blank of the definition, is it close to what the taxonomy says?
-
Visibility: Do the terms actually make all of the things going on in this system properly visible, and not ignored? Does it get updated as people’s lives and problems change, to incorporate these new terms?

If you have any insights into making a good taxonomy, or how you might use a giant list of people’s legal issues, please be in touch! And come explore our working version of LIST, as we build out all of the terms.
2 Comments
[…] Article URL: https://www.openlawlab.com/2020/10/06/taxonomy/ […]
Jphn: Some suggestions for topics;
Paternity: say establishing paternity; add Petitions for Custody, Parenting Time and Child support; Birth certificate: add Voluntary Acknowledgment of Paternity; Add spousal support and alimony section
Native Americans: custody, parenting time, child support, jurisdiction; add
Dissolution of Domestic Partnerships; add Same Sex Marriages and the courts; UCCJEA proceedings, determining jurisdiction over child custody matters.. Suggest review the table of contents to the 3 volume Family Law CLE for other topics